
Anthropic 已正式发布 Claude Opus 4.7,并将其定位为当前 Opus 系列的最新通用旗舰模型。从官方公告与早期合作伙伴反馈来看,这次更新重点不在于单一跑分提升,而在于复杂任务中的稳定性:包括更长时间的自主执行、更严格的指令遵循、更强的代码验证能力,以及更高分辨率的图像理解。
核心变化:不只是更强,而是更稳
Anthropic 对 Opus 4.7 的定义,基本可以概括为“面向生产任务的增强版 Opus 4.6”。其主要提升集中在以下几个方向:
- 更强的软件工程能力
- 更稳定的多步任务执行
- 更高分辨率的视觉输入处理
- 对长上下文与文件记忆的更好利用
- 在高难度工作流中的更低工具错误率
从产品角度看,这意味着 Anthropic 正在把模型能力从“会回答”进一步推进到“可交付”。
编码与代理执行仍是主战场
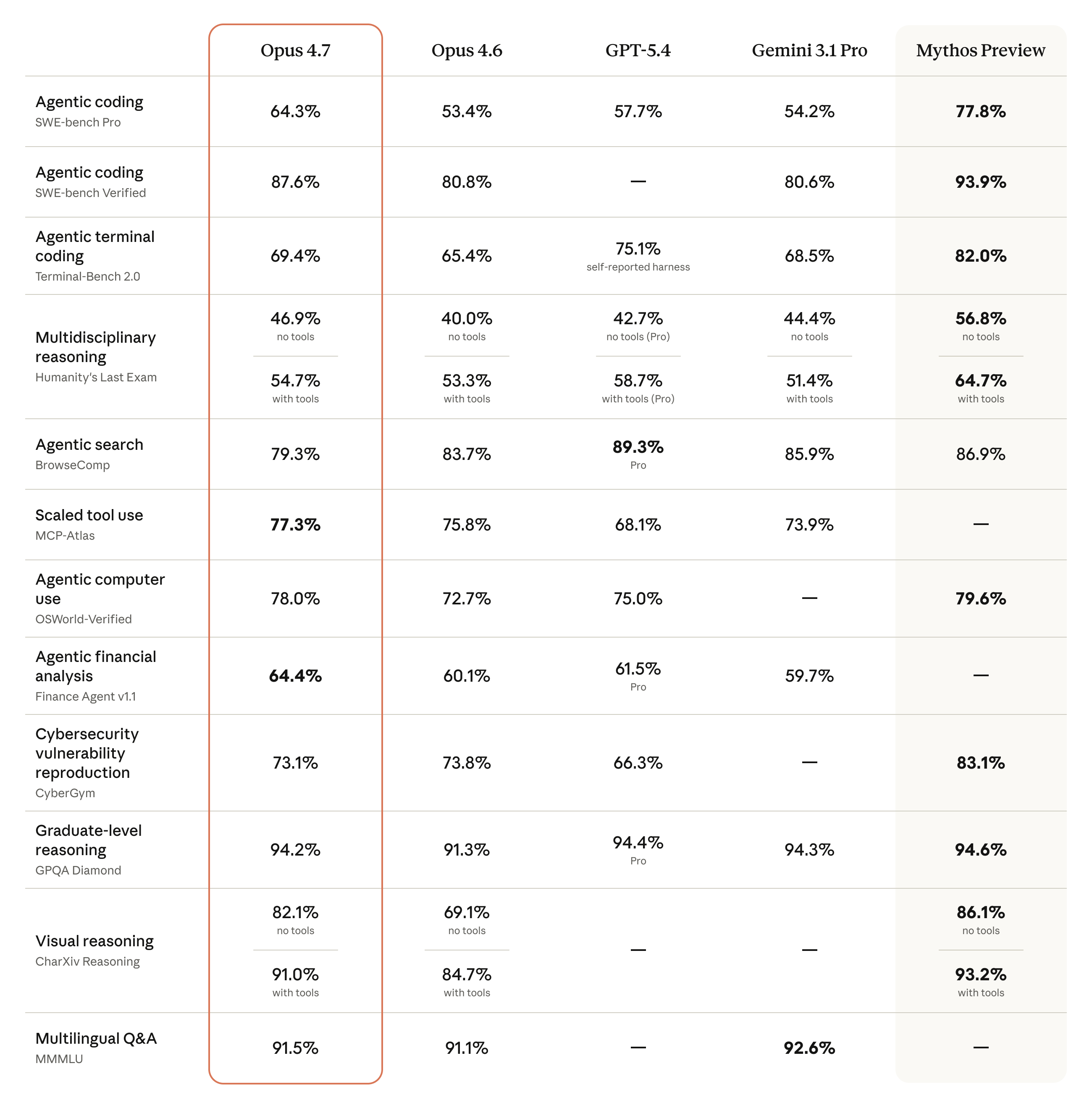
Anthropic 在公告中强调,Opus 4.7 在高难度软件工程场景中明显优于 Opus 4.6,尤其适合此前仍需要人工密切监督的任务类型。模型不仅能生成代码,还更强调自我校验:例如在提交结果前验证输出、检查逻辑一致性,并在工具链中持续推进任务。
这类提升对于 Agent 工作流尤其关键。对企业用户而言,真正影响体验的往往不是模型能否写出一段代码,而是它能否在多个步骤中持续执行、处理异常并维持结果一致性。
多模态能力继续升级
除编码外,Opus 4.7 的另一个重要变化是视觉输入能力的提升。官方表示,模型支持更高分辨率的图像处理,长边可达 2576 像素。这一变化看似参数层面的升级,实际却会直接影响很多生产场景:
- 对复杂界面截图的识别
- 对技术图纸、流程图和表格的读取
- 对高密度视觉信息的抽取与分析
对于依赖图像与文档理解的企业场景,这类改进往往比一般性的“多模态支持”更有现实意义。
早期合作伙伴反馈透露了什么
Anthropic 在公告中列出了多家早期测试企业的反馈。尽管这些反馈带有明显的发布期背书属性,但可以用来观察模型优化方向。
从公开信息看,Notion、Databricks、Replit、Shopify、Cursor 等合作方普遍强调以下几点:
- 复杂长任务的完成率提升:模型更少中断,更少出现执行到一半停止的情况。
- 工具调用更稳定:多步代理流程中的失败率下降。
- 代码更整洁:无意义包装逻辑和冗余兜底代码减少。
- 对上下文的利用更成熟:在长文件、长任务、多轮操作中更能维持一致性。
这说明 Anthropic 并没有把 Opus 4.7 单纯打造成“更高分的模型”,而是在尝试提升它作为生产工具的可靠性。
定价与部署方式保持不变
在商业层面,Anthropic 没有提高 Opus 4.7 的 API 定价,仍维持:
- 输入:5 美元 / 百万 tokens
- 输出:25 美元 / 百万 tokens
模型已在 Claude 产品线、Anthropic API 以及 Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 等渠道上线,API 模型标识为 claude-opus-4-7。
对于已有 Opus 4.6 工作负载的团队来说,这意味着升级门槛相对较低,主要成本仍然在于评估与迁移,而不是采购成本本身。
安全策略:在更强能力与更高风险之间找平衡
公告中另一个值得注意的点,是 Anthropic 提到 Opus 4.7 将作为新一代网络安全护栏的首批落地模型之一。公司同时强调,其尚未全面放开的更强模型 Mythos Preview 仍处于受限测试阶段,而 Opus 4.7 被用来先行验证相关防护策略。
这一做法反映出当前头部模型厂商的共同处境:模型能力越强,可用性与风险控制之间的张力也越大。对 Anthropic 而言,如何在提供更高生产力的同时控制高风险使用场景,将成为后续产品化的重要考验。
结语
如果用一句话概括 Claude Opus 4.7,这更像是一次“可靠性升级”而非单点性能升级。它的意义不在于展示某一项能力的戏剧性突破,而在于把复杂编码、多步代理和高分辨率视觉理解进一步推进到更接近实际可部署的水平。
对于开发者和企业用户而言,这种变化可能比单一榜单上的领先更有价值。